
但凡学习过数据结构和算法的人都了解排序算法。我也是,常常扯上两句,好像说得头头是道,但是一动手写代码就漏洞百出了。尤其最近深感排序算法的重要性,所以下定决心要好好把排序算法彻底弄清楚。
首先说个最简单的冒泡排序。由于它的简洁,冒泡排序通常作为第一个排序算法介绍给入门级的学生。
冒泡排序的思想:
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序是稳定的排序。
冒泡排序的复杂度:
冒泡排序对n个项目需要O(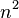 )的比较次数,且可以原地排序,而且它是稳定排序。尽管这个算法最简单,但它对于少数元素之外的数列排序是很没有效率的。
)的比较次数,且可以原地排序,而且它是稳定排序。尽管这个算法最简单,但它对于少数元素之外的数列排序是很没有效率的。
冒泡排序是与插入排序拥有相等的执行时间,但是两种算法在需要的交换次数却有很大的不同。在最坏的情况,冒泡排序需要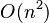 次交换,而插入排序只要最多
次交换,而插入排序只要最多 次交换。冒泡排序的实现通常会对已经排序好的数列拙劣地执行(),而插入排序同样情况可能只需要个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。冒泡排序如果能在内部循环第一次执行时,使用一个旗标来表示有无需要交换的可能,也有可能把最好的复杂度降低到。在这个情况,在已经排序好的数列就无交换的需要。若在每次走访数列时,把走访顺序和比较大小反过来,也可以稍微地改进效率。有时候称为往返排序,因为算法会从数列的一端到另一端之间穿梭往返。
次交换。冒泡排序的实现通常会对已经排序好的数列拙劣地执行(),而插入排序同样情况可能只需要个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。冒泡排序如果能在内部循环第一次执行时,使用一个旗标来表示有无需要交换的可能,也有可能把最好的复杂度降低到。在这个情况,在已经排序好的数列就无交换的需要。若在每次走访数列时,把走访顺序和比较大小反过来,也可以稍微地改进效率。有时候称为往返排序,因为算法会从数列的一端到另一端之间穿梭往返。
在空间上,冒泡排序只需要额外的O(1)的空间进行数据交换。
小结:
- 适合的数据结构:数组
- 最差时间复杂度:O(n2)
- 最优时间复杂度:O(n)
- 平均时间复杂度:O(n2)
- 最差空间复杂度:总共O(n),需要辅助空间O(1)
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
public int[] bubbleSort(int[] arr) { if(arr==null) return arr; int len = arr.length; for(int i=len; i>0; i--) { for(int j=0; j arr[j+1]) { int temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } } } return arr;} 上面是我第一次根据冒泡思想写的程序,大家看一下有什么问题。
其实上面的代码执行时结果是正确的,但有两个细节做的不太好。
- 一个是arr的判断。我们编程中应该培养一个良好的习惯就是尽量减少重复性的代码。像我上面的代码有两个return,完全可以合并。而且由于arr为空的情况实际较少(因为我们要进行排序必然要传入正确的数组,传入空数组应该是误操作,出现的概率比较小),所以从提供流水线指令预取成功率的角度考虑,我们把arr==null的判断变为arr!=null的判断可能更合适。
- 第二个是两层for循环中的那个内循环,那个i-1如上面所写放在条件判断处,每次都要执行减法,代价大。另外--i和++j的执行效率要比上面写的i--和j++执行效率高。
综上所述,我们将代码修改如下:
public int[] bubbleSort(int[] arr) { if(arr!=null) { int len = arr.length; for(int i=len-1; i>0; --i) { for(int j=0; j arr[j+1]) { int temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } } } } return arr;}
上面是java代码,下面再增加一段标准c语言的写法吧
#includevoid bubbleSort(int arr[], int count) { int i = count, j; int temp; while(i > 0) { for(j = 0; j < i - 1; j++) { if(arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } i--; }}int main(int arc, char* const argv[]) { //测试数据 int arr[] = {5, 4, 1, 3, 6}; //冒泡排序 bubbleSort(arr, 5); //打印排序结果 int i; for(i = 0; i < 5; i++) printf("%4d", arr[i]); }
如果大家只是想了解一下冒泡排序的思想及代码写法,那看到这里就可以结束了。如果想对冒泡排序有更多一点了解,那就接着往下看吧。
冒泡排序的核心就在两个for循环的处理上。我们上面的代码其实只实现一种写法。维基百科上用助记码的方式给出了三种方案。

对应的代码如下:
for(i = 0; i < count - 1; i++) { for(j = 0; j < count - 1 - i; j++) { if(cmp(arr[j], arr[j+1]) > 0) { temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } }}
for(i = count - 1; i > 0; i--) { for(j = count - 1; j > count - 1 - i; j--) { if(cmp(arr[j-1], arr[j]) > 0) { temp = arr[j]; arr[j] = arr[j-1]; arr[j-1] = temp; } }}
for(i = 0; i < count-1; i++) { for(j = i+1; j < count; j++) { if(cmp(arr[i], arr[j]) > 0) { temp = arr[j]; arr[j] = arr[i]; arr[i] = temp; } }} 上面我们已经分析过,冒泡排序的交换次数过多,所以效率不好。其实仔细观察发现,每一趟排序都会把最大值放到序列的末端,因此只需要将最大值交换到序列末端即可,中间的那些多次交换是不必要的。因此算法可以进行简单的改进:
for(right = count-1; right > 0; right --) { for(i = 1, max = 0; i < right; i++) { if(cmp(arr[i], arr[max]) > 0) { max = i; } } if(cmp(arr[max], arr[right]) > 0) { temp = arr[max]; arr[max] = arr[right]; arr[right] = temp; }}
不过注意,这样修改之后的冒泡排序就不再是稳定排序了。需要注意的是,排序算法是否为稳定的是由具体算法决定的,不稳定的算法在某种条件下可以变为稳定的算法,而稳定的算法在某种条件下也可以变为不稳定的算法。
另外,我们在时间复杂度分析的时候也了解到,有时序列已经排列好了,但是冒泡排序还在重复地遍历,而这时的遍历是不必要的。我们设想一下,如果在当前这趟遍历时,没有元素发生交换,那就说明排序已经完成,因此后面就不需要再进行排序了。通过设置标记或旗帜的方法来改进的思路如下:
#includeusing namespace std; void bubble_sort(int d[], int size) { //#假定两两交换发生在数组最后的两个位置#% int exchange = size - 1; while(exchange) { //#记录下发生数据交换的位置#% int bound = exchange; exchange = 0; //#假定本趟比较没有数据交换#% for(int i = 0; i < bound; i++) { if (d[i] > d[i + 1]) { //#交换#% int t = d[i]; d[i] = d[i + 1]; d[i + 1] = t; exchange = i + 1; } } }}int main (int argc, char * const argv[]) { int a[] = {3, 5, 3, 6, 4, 7, 5, 7, 4}; //#QQ#% bubble_sort(a, sizeof(a) / sizeof(*a)); //#输出#% for(int i = 0; i < sizeof(a) / sizeof(*a); i++) cout << a[i] << ' '; cout << endl; return 0;}
读到这里,长吁一口气,冒泡排序的学习就先到这里吧。下次学习 。
参考资料:
1.
2.